
快訊
- 4張圖表看川普關稅成績單 進口中國商品銳減、台灣貨不減反增
- 資金寬鬆有利支撐債市表現! IF策略掌握2026收益契機
- 極限攀岩家周六徒手攀登101 中英文拜拜!賈永婕:幹大事的勇氣
- 快訊/日本阿蘇直升機載2台人墜毀 警方一早重啟搜救準備
- 環島電網剩最後缺口!曾文生:「蘇花安」有望助台電接上「最後一哩路」
- 陳佩琪臉書洩官員個資 石明謹質疑違法「可能是律師…」 她認了不小心
- 美股重挫!台股早盤跌逾350點摜破5日線 台積電最低跌至1740元
- 赴日注意!本季最強寒流報到、影響至25日 北陸降雪恐達130公分
- 雷虎科技發重訊「嚴重損害聲譽」求償1億 網紅Cheap:不會退縮
- 競購華納兄弟 Netflix新提全額現金收購
- 網友發文稱前總統名字都好怪 釣出蔡英文本人神回「按讚破13萬」
- 馬克宏嗆美:歐洲不能屈服強權 俄羅斯見縫插針
- 兒子布魯克林掀家醜 貝克漢首度發聲「孩子被允許犯錯」
- 如何解決格陵蘭問題?川普:我們和北約都會滿意
- 美撥款委員會:應川普要求撥11.5億美元挺台防衛
- 美最高法院未對關稅案裁定判決 川普:很清楚就是合法
- 西班牙又出事!通勤列車撞擋土牆畫面曝 司機慘死、逾30傷
- 川普強取格陵蘭風暴、輝達台積電ADR全倒 台指期暴跌437點下探3萬1支撐
- 川普欲奪格陵蘭引發美股血崩!道瓊狂瀉870點 台積電ADR重挫近5%
- 川普自豪執政週年成果 再提台積電等企業擴大投資
Meta公布AI語音模型支援4000種語言! 以《聖經》為範本打造多國語言資料庫
2023-05-23 12:11 / 作者 戴嘉芬
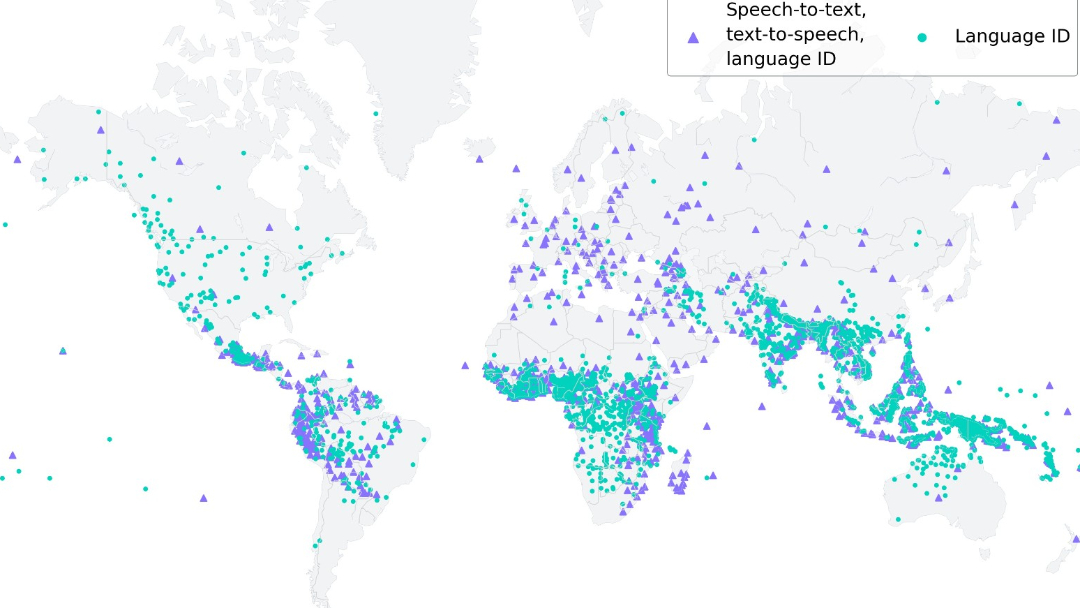
Meta今宣布該公司研發完成MMS大規模多語言語音模型,目前已可辨識超過4000種口語表達的語言。取自Meta
Meta去年曾發表「台翻英」在內的多國AI語音翻譯系統,如今又有新進展!該公司研發完成的MMS大規模多語言語音模型目前已可辨識超過4000種口語表達的語言,且支援語音轉文字的應用範圍已從100種語言增加到1100種,並完成多國語言版《新約聖經》有聲讀物資料庫。Meta表示,此技術還可應用於AR、VR,讓大家在虛擬世界中也能使用自己偏好的語言,而且聽得懂對方在說甚麼。Meta表示,世界上許多語言正面臨消失的危機,而現有的語言辨識與生成技術上的限制更加快此趨勢;該公司於今(5/23)發表系列大規模多語言語音模型(Massively Multilingual Speech AI;簡稱MMS),希望藉此幫助大家以自己習慣的語言,更輕鬆地獲取資訊及使用電子裝置。新版語音模型已可辨識超過4000種口語表達的語言,辨識量是既有技術的40倍
MMS並支援「文字轉語音」及「語音轉文字」的技術應用,至今已可轉換超過1100種語言,是過去的10倍。Meta並宣布,將開放這項技術的原始碼及模型,讓研究社群能夠以現有的工作成果為基礎繼續開發,一同保存全球的語言,加強人們的溝通,不受距離和語言因素而限制。。
過去最大型的語音資料庫最多僅涵蓋100種語言,因此開發此技術所面臨的第一個挑戰即為「蒐集數千種語言的語音訓練資料」。為了克服這項挑戰,Meta 使用已翻譯成多種語言、譯文已被廣泛閱讀及研究的宗教經典:《聖經》,作為語言的文字訓練資料。
《聖經》譯文有多種語言的公開錄音檔,作為大型多語言語音模型計畫的一部分,Meta創造的資料集,蒐集超過1100種語言的《新約聖經》有聲讀物資料庫,平均為每種語言提供32小時的語音訓練資料,後續又加入其他未標註的基督教有聲讀物後,可用的語言訓練資料已涵蓋超過4000種語言。
Meta表示,雖然資料集收錄的聲音以男性居多,但測試成果顯示,不論是男性或女性的聲音,此語音模型皆能同等準確地辨識。此外,上述的語言訓練資料大多為宗教相關的內容,但Meta分析顯示,這並不會使模型傾向於生成出更多的宗教性質的語言。
最新more>
- 同居男友販毒被逮 她出錢辦保後才知女兒遭偷拍
- 藍白擺出「清德宗」立牌!傅崐萁批賴掏空台灣40.5兆 黃國昌稱用憲法藥治憲政亂
- 打臉30秒說詞!綠委調監視器還原時間軸:黃國昌帶走機密文件1分15秒 長達42秒拍不到
- IG、Threads 都在騙!寒假想「在家躺著賺」 警揭打工文藏詐騙風險
- 兌現承諾!北一女校長考學測自然寫不完 坦言「數A會的不多」
- 4張圖表看川普關稅成績單 進口中國商品銳減、台灣貨不減反增
- 資金寬鬆有利支撐債市表現! IF策略掌握2026收益契機
- 離婚後爆秘戀「瘋男」晨灰、傳深夜進他家 蕾菈:真的只是好朋友
- 極限攀岩家周六徒手攀登101 中英文拜拜!賈永婕:幹大事的勇氣
- 磁暴不止影響通訊?有人頭暈、失眠 醫師曝「3類人」要注意
熱門more>
- 機體嚴重損毀!阿蘇直升機載2台人墜毀 事發時「煙+霧」一片白茫茫
- 賣3700元才賺750元?店家PO外送平台撥款金額 釣出一票苦主曝真相
- 恐怖虎媽浴室囚女900多天「活活餓死」 貓爸未伸援一併起訴
- 【太想聊日本】高市早苗止步相撲擂台! 「女人禁制」富士山也設結界?
- 「包吃住月薪4.8萬」行天宮徵才! 網喊「想投履歷」過來人分享:要神明點頭
- 《甄嬛傳》片尾曲原唱亂入西門鬧區搶麥 遭街頭藝人眼紅檢舉超尷尬
- 力積電又出招!擬增資發行GDR 總額不超過42萬張普通股 現價估算可募286億
- 皮蛇疫苗今開打民眾排爆 彰化補助太划算「2萬降到6千元」
- 反年改出包…公務員退休金沒變多!翁曉玲「沒寫施行日期」回應了
- 南韓《熔爐》案延燒…19身障女遭性侵 不只院長犯案、職員「用腳踩胸部」